cuda 编程学习:Grid-Block-Thread
cuda的软件层级
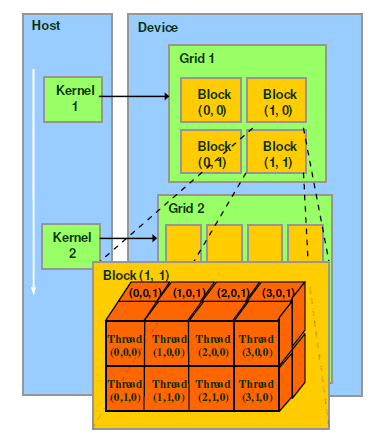
cuda的软件逻辑上包含Grid-Block-Thread三级结构,kernel可以理解为一次函数调用,生成一个Grid。
矩阵乘kernel为例编写cuda代码
调用kernel时,实际上传入了kernel_name<<<grid,block>>>参数。如上图,grid参数控制了一个Grid有多少个Block,block参数控制了一个Block里需要多少Thread,这两个参数都是三维向量,如下方矩阵乘的kernel定义:
// 定义线程组织结构
// 每个 block 包含 BLOCK_SIZE x BLOCK_SIZE 个线程
dim3 block(THREAD_SIZE_X, THREAD_SIZE_Y, THREAD_SIZE_Z);
// grid 的维度,根据输出矩阵 C 的尺寸(M x N)确定
dim3 grid(grid_size_x, grid_size_y, grid_size_z);
// 启动 kernel
matrixMulKernel<<<grid, block>>>(A, B, C, M, N, K);dim block也可以写成,Z方向默认为1
dim3 block(THREAD_SIZE_X, THREAD_SIZE_Y);定义好维度之后,在kernel函数里面就可以通过变量拿到执行thread的信息:
int grid_x = gridDim.x; // grid 在x方向的线程块数量
int block_y = blockIdx.y;
int block_y_dim = blockDim.y; // block在y方向的线程数量
int thread_x = threadIdx.x;如果我们要计算一个矩阵乘,可以这么写,注意B是转置后的矩阵,具有局部性,和数学上的不一样,这是一般矩阵乘编写时的习惯
__global__ void matrixMulKernel(const float * __restrict__ A, const float * __restrict__ B, float * __restrict__ C, int m, int n, int k) {
// A[M][K]
// B[N][K]
// C[M][N]
int i = blockIdx.y * blockDim.y + threadIdx.y;
int j = blockIdx.x * blockDim.x + threadIdx.x;
// 每个thread执行一行和一列的计算
if (i < m && j < n) {
float sum = 0.0f;
for (int l = 0; l < k; l++) {
sum += A[i * k + l] * B[j * k + l];
}
C[i * n + j] = sum;
}
}调用kernel前后的操作
调用kernel之前需要做一些准备工作:申请内存,内存拷贝,定义grid和block大小
调用kernel后需要cudaDeviceSynchronize();等待结果,这是因为kernel的调用是异步提交的任务,完成后拷贝内存和释放device内存。
void sgemm_cuda(float *A, float *B, float *C, int m, int n, int k) {
// 在设备端分配内存
float *d_A, *d_B, *d_C;
cudaMalloc(&d_A, M * K * sizeof(float));
cudaMalloc(&d_B, K * N * sizeof(float));
cudaMalloc(&d_C, M * N * sizeof(float));
// 将数据从主机拷贝到设备
cudaMemcpy(d_A, A, M * K * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, K * N * sizeof(float), cudaMemcpyHostToDevice);
// 定义线程组织结构
// 每个 block 包含 BLOCK_SIZE x BLOCK_SIZE 个线程
dim3 block(THREAD_SIZE, THREAD_SIZE);
// grid 的维度,根据输出矩阵 C 的尺寸(M x N)确定
dim3 grid((N + block.x - 1) / block.x, (M + block.y - 1) / block.y);
// 启动 kernel,传入矩阵维度 m, n, k
matrixMulKernel<<<grid, block>>>(d_A, d_B, d_C, M, N, K);
// 等待 kernel 执行完成
cudaDeviceSynchronize();
// 将结果从设备拷贝回主机
cudaMemcpy(C, d_C, M * N * sizeof(float), cudaMemcpyDeviceToHost);
// 释放设备和主机内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
}
cuda实际上的调度
软件层级是编写kernel代码才会出现的,实际上GPU在计算时只有SM存在,可以理解为CPU的一个core,一个SM可以执行成百上千thread的执行。
GPU在调度kernel的时候,会保证一个Block内的thread被分配到同一个SM(SIMT)。
NVIDIA在调度时,32个thread是一个wrap,wrap才是SM调度和运行的基本单元,一次并行执行相同的指令,一个wrap占用一个SM运行,可以理解为CPU的一个线程。
这样一来,一个block内的thread如果很多,就会有多个wrap,假如是512,则有512/32=16个wrap,这16个wrap的运行是轮流进入SM的,由SM的硬件(wrap schedule)负责调度。
完整代码
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include <time.h>
#define M 1024 // 矩阵 A 的行数,矩阵 C 的行数
#define N 512 // 矩阵 B 的列数,矩阵 C 的列数
#define K 512 // 矩阵 A 的列数,同时也是矩阵 B 的行数
#define BLOCK_SIZE 16
#define THREAD_SIZE 16
int64_t get_current_time_ns() {
struct timespec ts;
clock_gettime(CLOCK_MONOTONIC, &ts);
return ts.tv_sec * 1000000000 + ts.tv_nsec;
}
__global__ void matrixMulKernel(const float * __restrict__ A, const float * __restrict__ B, float * __restrict__ C, int m, int n, int k) {
int i = blockIdx.y * blockDim.y + threadIdx.y;
int j = blockIdx.x * blockDim.x + threadIdx.x;
// 每个thread执行一行和一列的计算
if (i < m && j < n) {
float sum = 0.0f;
for (int l = 0; l < k; l++) {
sum += A[i * k + l] * B[j * k + l];
}
C[i * n + j] = sum;
}
}
void sgemm_cpu(const float * __restrict__ A, const float * __restrict__ B, float * __restrict__ C, int m, int n, int k) {
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
float sum = 0.0f;
for (int l = 0; l < k; l++) {
sum += A[i * k + l] * B[j * k + l];
}
C[i * n + j] = sum;
}
}
}
void sgemm_cuda(float *A, float *B, float *C, int m, int n, int k) {
// 在设备端分配内存
float *d_A, *d_B, *d_C;
cudaMalloc(&d_A, M * K * sizeof(float));
cudaMalloc(&d_B, K * N * sizeof(float));
cudaMalloc(&d_C, M * N * sizeof(float));
// 将数据从主机拷贝到设备
cudaMemcpy(d_A, A, M * K * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, K * N * sizeof(float), cudaMemcpyHostToDevice);
// 定义线程组织结构
// 每个 block 包含 BLOCK_SIZE x BLOCK_SIZE 个线程
dim3 block(THREAD_SIZE, THREAD_SIZE);
// grid 的维度,根据输出矩阵 C 的尺寸(M x N)确定
dim3 grid((N + block.x - 1) / block.x, (M + block.y - 1) / block.y);
// 启动 kernel,传入矩阵维度 m, n, k
matrixMulKernel<<<grid, block>>>(d_A, d_B, d_C, M, N, K);
// 等待 kernel 执行完成
cudaDeviceSynchronize();
// 将结果从设备拷贝回主机
cudaMemcpy(C, d_C, M * N * sizeof(float), cudaMemcpyDeviceToHost);
// 释放设备和主机内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
}
int main() {
// C = A * B, 注意B的存储模式并非常规的行优先,而是列优先(转置),这是为了局部性
// A[M][K], B[N][K], C[M][N]
float *A = (float*)malloc(M * K * sizeof(float));
float *B = (float*)malloc(K * N * sizeof(float));
float *C = (float*)malloc(M * N * sizeof(float));
// 初始化矩阵 A 和 B
for (int i = 0; i < M * K; i++) {
A[i] = (float)rand() / RAND_MAX;
}
for (int i = 0; i < K * N; i++) {
B[i] = (float)rand() / RAND_MAX;
}
for (int i = 0; i < M * N; i++) {
C[i] = 0.0f;
}
int64_t start_time = get_current_time_ns();
sgemm_cpu(A, B, C, M, N, K);
int64_t end_time = get_current_time_ns();
printf("sgemm_cpu time: %ld ns = %f ms\n", end_time - start_time, (end_time - start_time) / 1000000.0);
start_time = get_current_time_ns();
sgemm_cuda(A, B, C, M, N, K);
end_time = get_current_time_ns();
printf("sgemm_cuda time: %ld ns = %f ms\n", end_time - start_time, (end_time - start_time) / 1000000.0);
}